- A+
所属分类:学术文献
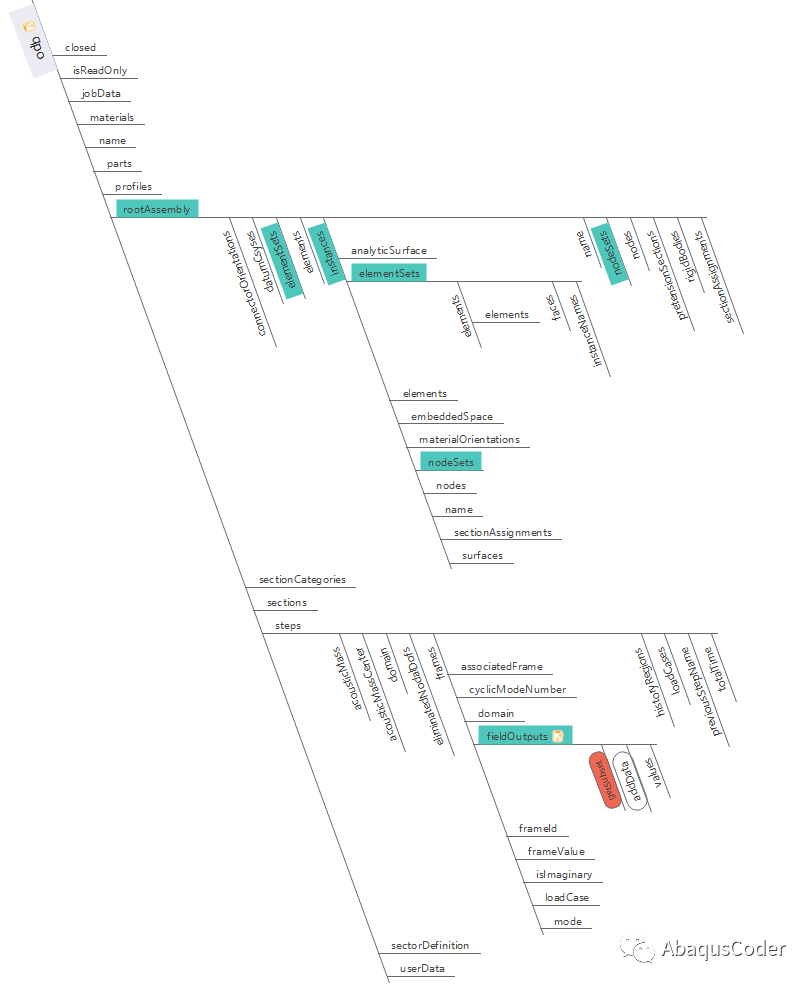
python是一种面向对象的高级语言, 那么在使用python处理odb的时候就要着手于对象, 将odb文件的对象谱系梳理清晰. 在完成上述工作之后, 再进行后处理二次开发的时候就可以直接按图索骥, 快速找到自己需要使用的方法了.
01 解析过程中的重要工具
ABAQUS为其定义的所有类提供了两个特别有用的方法:
- object.__methods__: 可以查看该类内部的所有方法
- object.__members__: 可以查看该类内部的所有属性
这两个方法为梳理ABAQUS对象谱系起到了很大的作用, 避免了使用python自带的dir方法(因其将对象内部所有的方法与属性同时返回, 导致解析困难).
ABAQUS还提供了优化了的print方法, 该方法位于ABAQUS的textRepr中, 名为prettyPrint.
使用该方法进行对象输出的效果如下:

在ABAQUS二次开发的时候要灵活运用这三种方法, 不仅可以提升效率, 还可以拓展自己对ABAQUS体系的认知.
02 odb文件的对象谱系
在该系列文章之前, 我已经梳理了一部分的odb文件对象谱系(之所以使用谱系这个名字, 是因为我感觉面向对象的思想就像一个大家族一样父子相承), 当然也许在更新过程中会有一些新的更新, 我会在系列结束后再次更新该谱系:

我的微信公共号
我的微信公招扫一扫



